Executive Summary
Summary of methodologies:
•Data Collection via API, SQL and Web Scrapping
• Data Wrangling and Analysis
• Interactive Maps with Folium
• Predictive Analysis
• Machine Learning Prediction
Summary of all results:
• Explotary Data Analysis along with Interactive Visualizations
• Predictive Analysis
Introduction
Project background and context: Space X promotes the launch of Falcon 9 rockets on its website for 62 million dollars, which is considerably less expensive than other providers who charge at least 165 million dollars per launch. The major reason for this price difference is that Space X can recycle the first stage. Thus, it is possible to estimate the cost of a launch if we can predict whether the first stage will land.
This knowledge can be advantageous for another company that wishes to
compete with Space X for a rocket launch contract. The objective of this
project is to establish a machine learning process to anticipate the success of the first stage landing.
Problems you want to find answers:
The aim of the project is to forecast whether the initial stage of the SpaceX
Falcon 9 rocket will accomplish a successful landing.
SECTION 1 — METHODOLOGY
Data collection methodology:
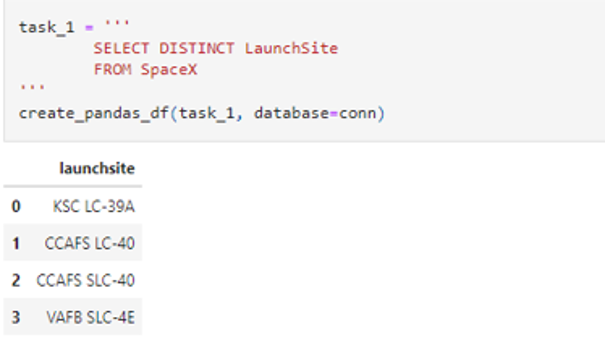
• From SpaceX Rest API
• Web Scrapping
Perform data wrangling:
• Encoding data fields for machine learning and dropping irrelevant columns
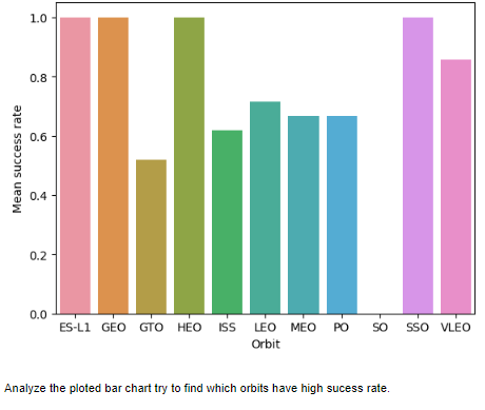
Perform exploratory data analysis (EDA) using visualization and SQL
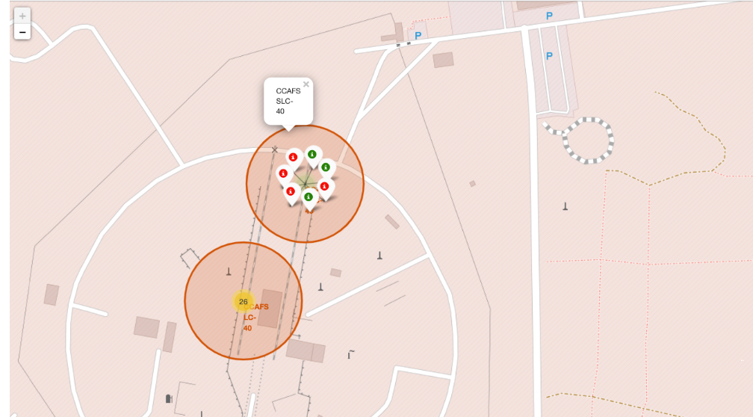
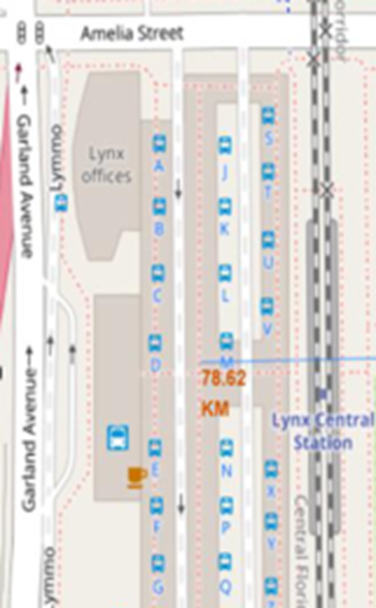
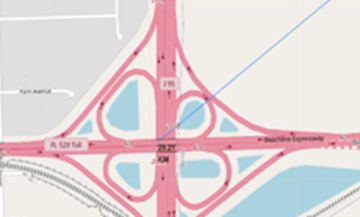
Perform interactive visual analytics using Folium and Plotly Dash
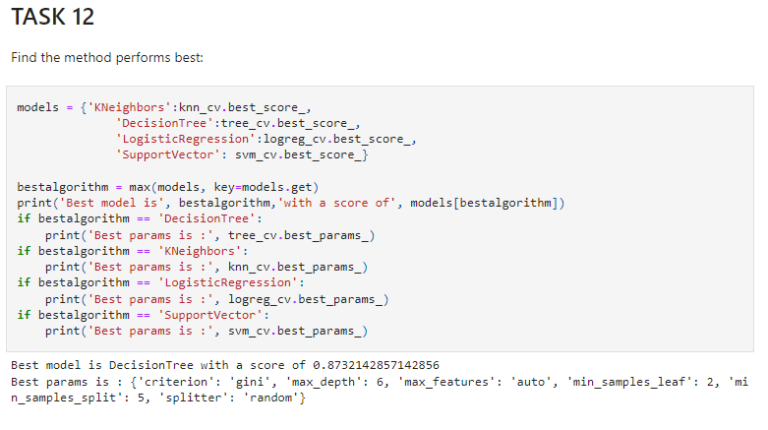
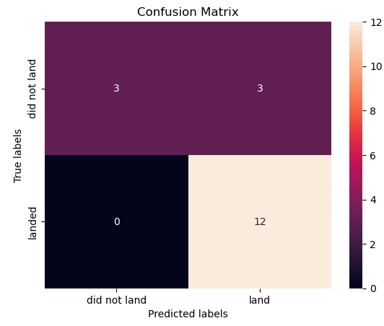
Perform predictive analysis using classification models
• Building and evaluating classification models
DATA COLLECTION
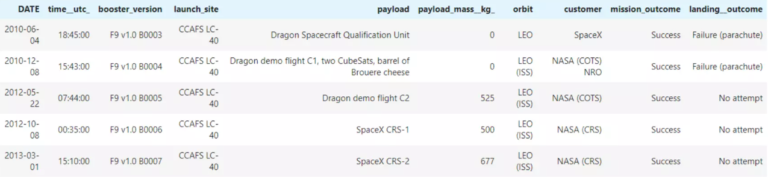
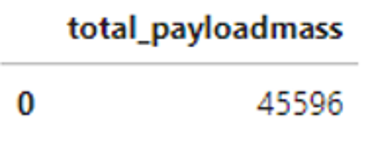
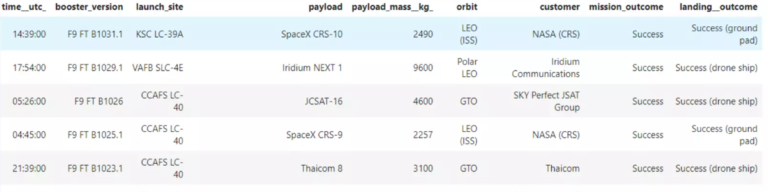
The data about SpaceX launches can be obtained from the SpaceX REST API. This API provides information about the rocket used, payload delivered, launch specifications, landing specifications, and landing outcome in JSON format
Then cleaned the data, checked for missing values and fill in missing values where necessary.
An additional frequently used method for acquiring Falcon 9 launch information is web scraping Wikipedia by utilizing the BeautifulSoup tool. The data is extracted from Wikipedia and is saved in a CSV file through the process of web scraping.